Mirror, mirror on the wall… AI (Deep Learning) needs to learn it all
A startup that I guide was building a system in which one key function was tracking people. Back-end was an AI (artificial intelligence) — Deep learning system. Given my background in building a series of products, I asked them to put a mirror in the path of people to test the system. Lo & behold now the system was double counting. This and more such examples of companies have set me thinking about how to release products using deep learning systems (Deep Learning is a field of study that gives computers the ability to learn without being explicitly programmed. They learn and gain Artificial Intelligence by being taught examples). This article is a commentary on some aspects of this.
As a brief context, a plethora of machine vision based analytic systems are being built today and have captured the imagination of people like counting people in retail stores, face recognition in phones, self-drive cars (autonomous driving), navigate air taxis etc. These systems use video cameras to capture the face/ scene and then use AI/ Deep learning model/ algorithms to figure out what the machine sees. The below commentary is on building products in such applications.
To illustrate let us look at counting cats instead of people in the picture below. The first picture is the original I fed into a state-of-the-art deep learning based object identification system which is hosted by an “algorithms on the cloud” company invested into by one of the biggest internet companies around. (Note: this article uses this algorithm but is not a commentary on its performance. It is primarily used as it is state of the art and makes it easy to demonstrate the lessons below). The second picture shows that a state of the art object detection algorithm detects 2 cats as there is a mirror… the machine “memorizes” cats but can’t “reason” out and “understand” that there is only one cat and detect the mirror. It even puts a higher probability to the reflected cat!!!


You get the drift. If you are building a machine that detects objects like humans do, an inability to detect reflections is detrimental to product release.
Let us take a real-world example of autonomous cars which uses video as a key input. You have parked your car and this is what the car(machine) sees. A building facade reflecting cars. How does the machine “understand” that the cars are behind you though you see them in front of you and accordingly instruct the self-driven car to reverse or move forward?


These scenarios are plenty. Here is one more illustration. How do you read this situation… see figure 2 — is there a building (clock tower) in front of the vehicle or is the vehicle on a road in front of a tram?



These are “edge cases” of any product development and needs to be considered upfront. However, there is a difference when it comes to building Deep learning systems. What is it and how to address? Let me illustrate product development considerations through the following 4 ways
Tweak model
Increase threshold in existing model: There is a confidence level associated with every object (which is here plotted for your understanding). A straightforward way would be to increase the threshold. In the tram example when I do that the building (clock) goes away (Figure 3). Great, this solves the problem. We have to be careful here to double check if we are losing any crucial information. The below typical street scene will illustrate this aspect. Like in the tram example here too we detect objects (pedestrians) in the puddle and more critically we detect a traffic light in the reflection which will confuse the machine in the vehicle.


We can increase the threshold but as can be seen below while the reflected pedestrian goes away we also miss some crucial information like the actual traffic light, the vehicle at a distance and a few pedestrians that are not identified. Increasing threshold is a strategy but beware of this risk

Retrain model
To overcome the above, a second strategy would be to train the deep learning system with images that factor in these anomalies and not allow rotation in-variance (inverted humans are not recognized as humans) which some models are trained on. The whole deep learning model/ layer architecture including weights and connections will change. This is different from traditional software development where “bugs” or “features” can be potentially added into applicable modules without changes to the whole system. Retraining takes time, resources, and more importantly, a sizable number of “edge cases” data points is required. Every edge case would lead to re-training the model.
Wasn't this precisely what the V-model of software development took care of? The requirements are verified and validated in parallel through testing. The edge cases are factored into the requirements. This would ensure that the building of the deep learning model (which spans design, coding to system testing boxes) evolves along with the validation of the edge cases. Will the product development process be agile by iterating through multiple Vs?
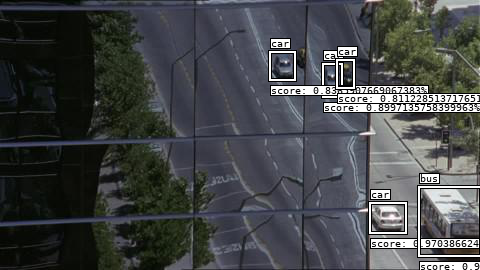
To illustrate I retrained using a different architecture and the below picture was obtained. The people information is not lost. The actual traffic light above is identified but not the reflection. The reflection of the person is classified as a “bird” and can be dealt with.

Use a different model
Person as a bird is still not comforting. This is when a completely different model or approach would come into consideration. Recursive classification will help ex: remove the bird from above picture. But is there a different model?
Since a vehicle will capture a video and not just an image you can use the time dimension to build a model. Time can be used as a third dimension and frames of images can be analyzed. This would mean moving from 2D (dimensional) deep learning networks to 3D. The traffic light will stay put but the person’s reflection will go beyond the puddle and vanish. Technically speaking moving from 2D convolution networks to 3D would qualify as a way under this approach. There are many more.
Augment with other sensors
What if there is no time to wait for the reflection to move away? Imagine more stringent use cases like Air taxis where speeds are higher. Uber Elevate, Airbus Vahana etc are vigorously developing flying taxis. As these air taxis come closer to the ground to pick up passengers they would face similar situations. See below a picture that would be close to a landing pad like a helipad. With concepts like landing in parking lots, helipads and on top of buildings you clearly don’t want to interpret this as a road with cars. Time available to react to such situations would put constraint even on 3D models like the one described previously.
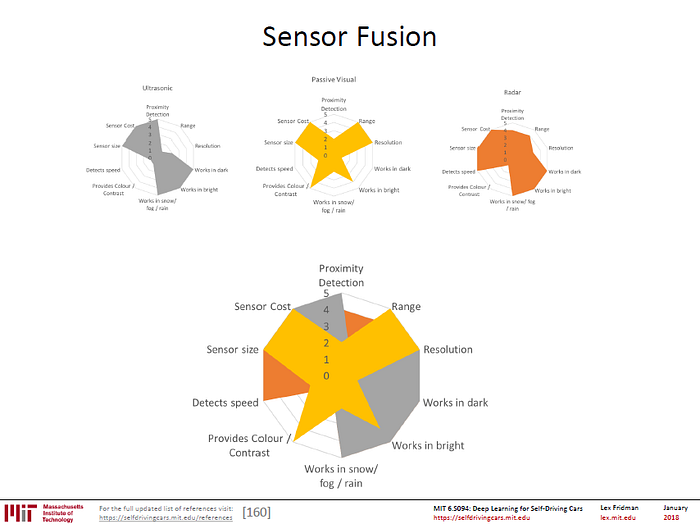
This is the point at which one starts considering other sensors to augment/ complement what is seen. In the vehicular context, LIDARs, for example, can give depth information but are currently expensive. RADARs are less expensive and perform better in different weather conditions but have lower resolution are two examples. Below is an MIT Self Driving car program thinking of how sensors can complement visual image based sensing to cut across functional & cost aspects. The building is detected with clear depth using these sensors and the difference between it and the road is also taken as an input into the machine.
This decision to add sensors is crucial as it moves one from deep learning to hardware sensors domain. Other aspects of hardware architecture, placement of sensors etc come in and in addition fusing of sensor data into the deep learning model, needs to be considered where appropriate. Concatenation of sensor data and vision data would change the deep learning model.
To re-emphasize how crucial the above 4 paths are one needs to look no further than the self-driving car market today. Usage of LIDAR is at the heart of the tussle between Google (Waymo), Tesla and Uber. While Elon Musk has famously stayed away from using LIDAR and concentrating on vision and few other sensors Google has it as a core component. LIDAR architecture has also been at the core of the legal tussle between Google and Uber.
In summary, the key aspect of developing products using deep learning is to think which approach is suitable upfront. Product development methodologies like mission scenario planning will help to arrive at this. So will lot of other product building frameworks. The trick is in the doing. Get a hold of the path upfront and doing it.
When you start feeling all cases are covered I would throw the below situation in. Sticker folks and not a reflection… back to drawing board. The answer cannot always be the “path 4” !!!


